2020 has been a strange year for obvious reasons that have affected all of us. At the start of the year, as I was heading into a new job, I half-jokingly told myself “this is a good time to lock yourself in a room and learn as much as possible about robotics” … Little did I know how literally this would come true, for better or worse.
Despite how awful this year has been in terms of living one’s normal life, sometimes it helps to look back on good things that happened.
- New job: In January 2020, I started at MIT CSAIL as part of the Robust Robotics Group. The environment shift from structured corporate to scrappy academic has been quite the contrast, but most importantly the learning opportunities at a place like MIT have been absolutely invaluable.
- New website: You’re currently reading it! Educating has been one of the aspects I miss most from my previous job. Needless to say, my colleagues at MIT are all brilliant folks and I don’t have a whole lot to teach them (yet…), so this site has been a nice platform to continue sharing knowledge with the world.
- New courses: Earlier in the year, Udacity offered a free month, during which I buckled down and completed their Deep Reinforcement Learning Nanodegree (I would suggest taking more than a month if you can). Later in the year, through employment at MIT, I was able to enroll in Professor Russ Tedrake’s Robotic Manipulation class.
In this post, I will do a deep dive into my main project at MIT CSAIL for 2020. I believe it serves as a good summary of what I’ve learned this year while presenting some substantial technical content.
Software Infrastructure for Home Service Robotics
Quick background: Toyota Research Institute (TRI) has research collaborations with several universities, one of them being the Toyota-CSAIL Joint Research Center at MIT. This comprises various projects in automated driving and home service robotics. Toyota is well-known for making cars, but — yes — they also make robots.
One of TRI’s research platforms is the Human Support Robot (HSR), which CSAIL has access to through this collaboration. Researchers involved in TRI projects would occasionally use the HSR for some demonstration or experiment, but there was nothing official as far as software infrastructure. I came in at the start of 2020 as an engineer to focus on developing software for this platform to speed up the path for research to find itself in real-world robot experiments with the HSR.
I colloquially describe the HSR as a robot capable “a little bit of everything”. It consists of an omnidirectional mobile base with a 5 degree-of-freedom manipulator, has a 2D lidar for navigation, and is equipped with several cameras: an RGB-D camera and a stereo camera pair on the head, plus a gripper camera. It runs ROS which makes it easy to connect to other software modules.
Chapter 1: Software and Basic Behaviors
So I came into the new job, unboxed a new version of the HSR we’d recently received, and my first task was to equip the HSR with your typical basic robot capabilities. I describe these in my Anatomy of a Robotic System post.
Navigation: Not much needed to happen here. The HSR already is pretty tied to the ROS Navigation stack and open-source SLAM tools like hector_slam, so with some ROS magic and tweaking of parameters (my favorite…) we were able to use those tools as-is.

Vision: I mentioned earlier that the HSR has its fair share of cameras, which makes sense because vision is a very important sensor for complex household tasks. Perhaps the biggest vision-only achievement was standing up an object detector training pipeline using Facebook AI Research’s Detectron2 library, as I discuss in my previous post. This allowed us to train object detectors both for simulation and real-world demonstrations.

(Source: Object Detection and Instance Segmentation with Detectron2)
Manipulation: Once the robot detects an object, we generally want it to do something with the object — typically some kind of manipulation task. While the HSR already includes a good set of low-level manipulation software, including inverse kinematics and the ability to add collision primitives to the world, there was still more to do.
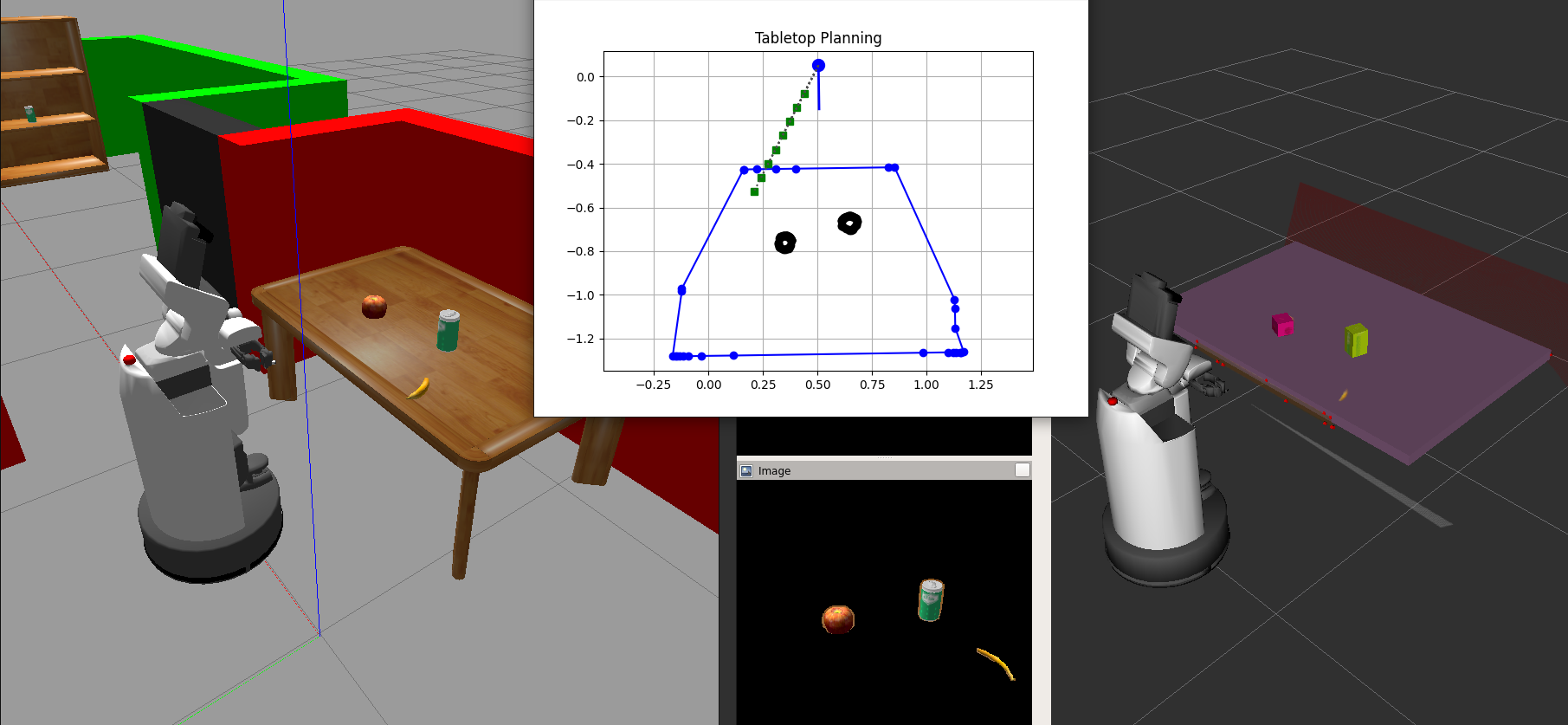
Perhaps the most interesting thing I got to work on was our tabletop planner pipeline which couples perception and manipulation. The HSR software stack includes a utility to segment a point cloud from the head RGB-D camera into a horizontal tabletop and separate the object clusters on that tabletop. We augmented this in a few ways:
- Fit simple box primitives around the convex hulls of the tabletop and object and added them as collision primitives for the HSR’s built-in motion planner.
- Used our object detection pipeline to find the correspondence between (unlabeled) 3D point cloud clusters and detected objects.
- Used the dimensions and pose of the estimated 3D box primitives to come up with a grasp plan (i.e., a target gripper pose to manipulate an object).
For example, in the image below the banana is our target grasp object so it does not a have a collision box around it on the right. However, this box is still used to determine that the robot should use a top-down grasp oriented roughly perpendicular to the table to pick up that banana.
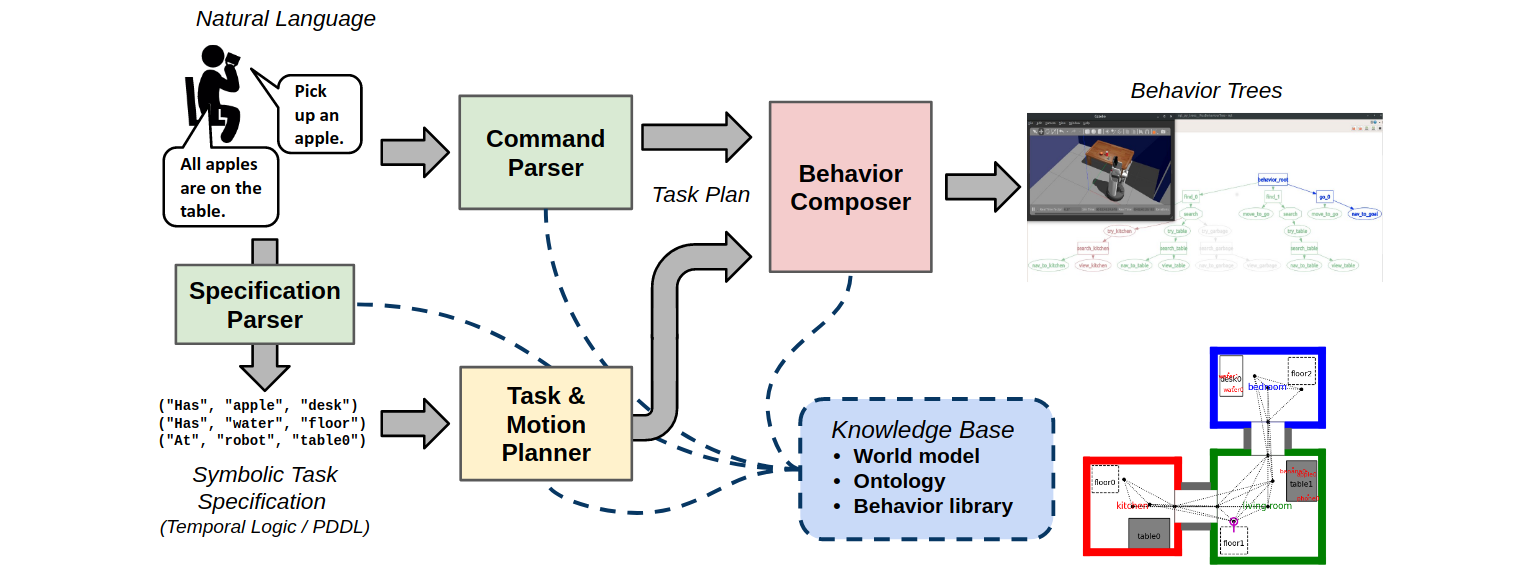
After proving out the basic capabilities, I put them into behavior trees, which are a way to manage complex tasks for applications such as robotics. Behavior trees allow composition of individual behaviors in various forms such as sequential or parallel order, or even encoding priority in tasks. An important element of behavior trees is that they can be “ticked”, or run through in discrete steps, and the result of each tick is a status variable such as success, failure, or running. This way, you can program autonomous systems that are robust to failures in the low-level execution of behaviors.
Without getting into too much technical detail, below are some common types of tasks you can express using behavior trees, along with examples in plain English:
- Sequence: “Go to the table, look for a banana, and pick up the banana.”
- Parallel: “Look for a banana while moving to the table.”
- Fallback: “Pick up a banana with a side grasp. If that fails, try a top-down grasp.”
For a great introduction to behavior trees, check out this book by Michele Colledanchise and Petter Ögren, or my own blog post on behavior trees. As for software tools to implement them, I have enjoyed using the py_trees Python package by Daniel Stonier, even though I’ve been “stuck” with an older version since the HSR uses Ubuntu 18.04 and ROS Melodic at the time of writing this.

Chapter 2: Natural Language Understanding
Once we could string together a set of core behaviors, the next goal was to see if we could command these behaviors by actually speaking (or typing) to our robot. It was at this point earlier in the year that I decided to do a little brushing up and write my Introduction to Natural Language Processing post, which comes with a full presentation video and GitHub repo.
I didn’t want a highly constrained system where users had to say exactly the right thing or the robot would be rendered useless, so I knew some machine learning would have to happen. However, I also didn’t necessarily want a completely end-to-end pipeline with a massive neural network since those require a lot of training data and/or compute (yeah, I’m looking at you, transformers).
Our pipeline began with a neural network that would accept a word sequence of arbitrary length and produce a classification output describing what the robot should do. This required the definition of discrete categories that tied to the behaviors from the previous section (navigation, vision, and manipulation) as shown in the following table.
| Input Sentence | Action | Object | Room | Location |
| “Move to the kitchen” | Go | unknown | Kitchen | unknown |
| “Grab a red apple from the kitchen table” | Pick | Apple | Kitchen | Table |
| “Look for a banana by the ground” | Find | Banana | unknown | Floor |
To get specific, the architecture I chose was a Recurrent Neural Network (RNN). First, the natural language input sequence is embedded using pretrained GloVe word embeddings. The network consists of two bidirectional Long-Short Term Memory (LSTM) layers with hidden dimension 32, as well as a feedforward attention layer which helped enormously with classification accuracy. It looks like the diagram below, but with multiple classification outputs according to our input/output table. This was all done using PyTorch.
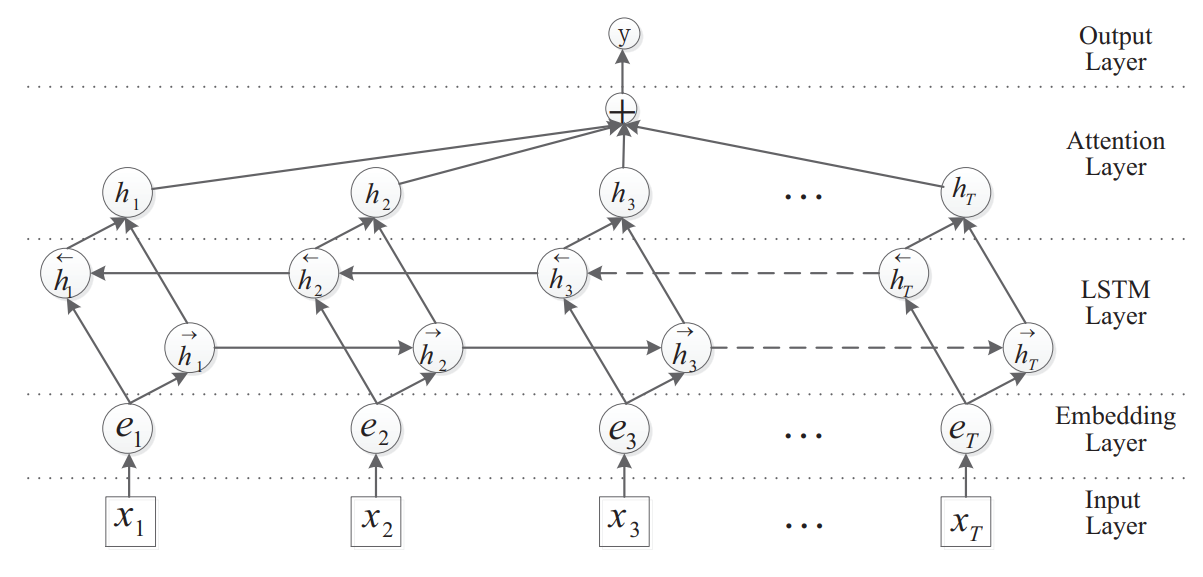
Source: Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification, Zhou et al. (2016)
After running an input text sequence through the trained network, the robot would use its (hard-coded) knowledge of the world to figure out what to do — in other words, it would generate a behavior tree using the network outputs as symbolic parameters. To avoid having to hand-annotate training and test data, I also spent some time writing tools to automatically synthesize sentences given a couple of sentence templates and/or synonyms for keywords. Totally worth the effort for small problems like these.
So far so good, but a few more questions remained:
- What if the input consists of multiple sentences with co-references? (e.g., “Pick up the apple, go to the living room, and put it on the table”)
- What if we have ambiguous sentences? (e.g. there are 2 apples in a scene but they can be differentiated by relationships to other objects, such as “the red apple to the left of the cup”)
To do this, we employed a combination of machine learning and more traditional approaches. First I tagged the sentence’s parts of speech with a pretrained English language model from the Stanza package from Stanford. I then parsed the sentence into a tree using a manually defined grammar with NLTK. This parse tree was used to break up individual sentences and convert complex expressions to simplified versions (for example, “the big red apple on the left” became “the apple”). Each simplified sentence was then passed into our classification RNN to interpret which action(s) the robot should take.
The complex referring expressions, on the other hand, could be passed into a variant of work that previously done in our research group (Roy et al. 2019). This network, named GroundNet, accepts visual input in the form of an image already labeled with object bounding boxes and return which of the bounding boxes best corresponds to the referring expression. Our modifications to GroundNet were twofold:
- We made this work with actual images from a robot platform (simulated and real) using our trained object detectors rather than a dataset with purely ground truth detections.
- We handled the case of an “incorrect” referring expression so that, instead of always returning one of the object detections in the scene, we could also identify that the expression doesn’t actually refer to anything valid. This was done by synthesizing “incorrect” training data and adding an extra classification output to the network.
The slideshow and video below illustrate this entire process, so check them out!

[1/6] Words in the sentence are tagged with parts of speech and then decomposed into chunks (such as Noun Phrases [NP] and Verb Phrases [VP]) using a manually defined grammar. 
[2/6] A variation of GroundNet is used to associate a complex referring expression with a bounding box from an object detector in a real visual scene. 
[3/6] We perform basic coreference resolution to link vague sentences like “Pick it up” to previously referenced objects. 
[4/6] Our modified GroundNet architecture. 
[5/6] An example showing a valid symbol grounding using GroundNet. 
[6/6] An example showing an invalid symbolic grounding using GroundNet.






Chapter 3: Task and Motion Planning
Once we had a set of composable behavior trees, it was time to go higher up the chain of abstraction. Instead of commanding a robot to perform a laundry list of actions, could we instead specify a goal and have the robot figure out a list of actions to achieve that goal? These types of problems are known as Task and Motion Planning (TAMP).
I quickly realized I needed a way to prototype and test my task and motion planner without relying on a full 3D simulator (Gazebo), or worse, the real robot. As a result, I took some time to develop a 2D world modeling framework that captured the home environment structures we cared about: A world with several rooms, potential object locations (furniture/floors), and objects to manipulate. The idea is to plan in these simple worlds before moving to the 3D simulation — and then, of course, the real robot. To make this process easier, I also built a tool to automatically convert the 2D worlds to Gazebo worlds. This effort paid off right away, especially considering the COVID-19 pandemic knocking me down to working on my personal laptop and severely limiting lab time with the real robot.

Now it was time to create abstractions that allowed us to plan in these worlds. I was first inspired by a few projects going on in our group, in which task specifications expressed in Linear Temporal Logic (LTL) were used to guide behavior for navigation and mobile manipulation tasks. In essence, my implementation was a modified version of the Towards Manipulation Planning with Temporal Logic Specifications paper by He et al. in 2015. A few details:
- A task specification describes the desired state of the world in temporal logic, e.g.,
F(all_apples_on_table ∧ X one_banana_on_floor)— or in (sort of) plain English, “eventually all apples on table and next a banana on the floor”. This then gets synthesized into a Deterministic Finite Automaton (DFA) which enables several formal methods techniques. - The state of the world consists of an enumeration of the locations of all the robot and the objects, for example represented with the string
robot.floor0::apple0.floor0::banana0.table1. - Transitions between states involve an action. For example, the action
MOVE(banana0,floor0)will transform the state above torobot.floor0::apple0.floor0::banana0.floor0. - Each state in this representation is associated with labels that represent our propositions in the task specification. For example, the post-action state above can be labeled with
one_banana_on_floorsince this proposition is true in that state. This framework is referred to as a Labeled Transition System (LTS). - Planning is done by taking a Product Automaton (PA) of both the DFA and the LTS, so now we essentially have a graph where each node corresponds to a pair of states in the DFA and the LTS and each edge denotes a specific action. At this point, we can apply our favorite search technique to find a plan from our (known) initial state to an accepting state.
As in both the 2015 paper and my colleagues’ project, I used the Spot software library to implement this planner. It worked fine, but I quickly learned that enumerating the states of all possible robot and object locations grows exponentially and is quite impractical beyond a handful of objects and locations. Despite using tricks like incrementally building the product automaton instead of enumerating all states at the start, or using Monte Carlo Tree Search instead of full search, things were pretty slow. It was nonetheless a good learning experience, and may be worth revisiting once we figure out more clever ways to formulate problems.

This is when I was pointed to another TAMP framework called PDDLStream, which was developed by Caelan Garrett, our next-door neighbor at MIT CSAIL’s Learning and Intelligent Systems Group. This combines the long-standing Planning Domain Description Language (PDDL), which has been used for planning in “old school” symbolic AI applications, with more modern sampling-based techniques for motion planning. The idea is to combine symbolic planning, where actions span a finite, discrete, and often small set of options, with the probabilistic completeness of sampling-based approaches to pick values for actions that may have a continuous set of parameters. This something that “plain” PDDL historically has not been able to handle, even though the real world is continuous.
After some time, I emerged from the learning curve with a really nice planning domain and stream definition that could be used in PDDLStream to generate task plans with both discrete and continuous parameters. PDDLStream comes equipped with a set of heuristic-driven search algorithms from the Fast Downward library — most notably a family of “focused” algorithms that assume the existence of continuous parameters before they are verified to see if there is an overall symbolic plan that satisfies a goal. If such a plan exists, sampling is then done to try fill in those missing parameters. This presents an interesting design tradeoff between searching over actions and sampling action parameters, which after some tuning has allowed us to solve much more complex problems compared to the LTL based predecessor.
Putting it all together, our system looks as follows. Natural language guides task and motion planning, which in turn guides the synthesis of complex behavior trees. So far we are relying on a fairly extensive knowledge base to make this all happen, but it’s a start. Going forward, there ideally will be more research projects that move us away from the realm of hard-coded information in certain areas.

Actually, this work culminated with one final addition which I used as my project for Russ Tedrake’s Robotic Manipulation class. Household robots generally need to open and close household things. In my project, I augmented our planning domain with an open/closed status for locations, and developed a simple point cloud registration method to open and close drawers in simulation and in real-world experiments. The video below explains the TAMP framework in general and shows the simulated and real robot in action, so do not miss it!
2020 Recap + 2021 Outlook
Glad you’ve stuck around until the end. The length of this post is testament to how much I’ve learned on the job in 2020 while working on home service robotics applications with the Toyota HSR. I’ve summarized the learning themes below.
- Re-immersion into Python: My Master’s project was all in Python and I had been using it here and there for classes, but after spending years mostly using MATLAB and Simulink, this was a return to doing significant project work with Python and being deliberate about Python 3 given that my MIT start date coincided with the retirement of Python 2.
- Software development crash course: Our research group places a premium on software development practices. It’s nice being in a group that does everything: Git, Docker, unit testing, continuous integration, etc. I’ve learned a lot from the way our group handles software — special shout-out to Greg Stein and Will Vega-Brown for their contagious fanaticism of the Docker + Makefile workflow!
- Hands-on with PyTorch: Prior to 2020 I might have used PyTorch to make a simple fully-connected network at some point. This year, I got to a) build my own RNN for classifying action parameters from sentences b) train object detectors using Detectron2, and c) dig into the GroundNet code base for updates and integration into our robot pipeline, with the invaluable help of Michael Noseworthy.
- Task and Motion Planning (TAMP): After hearing about behavior trees for a while from folks in RoboCup, I finally implemented my own! Then, I experimented with task and motion planning frameworks based on LTL and PDDL.
Yet, it feels like I’ve only scratched the surface as I’ve been catching myself up to the state of the art. Robotics and AI are fast-moving areas with no lack of new things to pick up, and consequently I look forward to continuing my learning in 2021. Some key things that come to mind:
- More work on home service robotics: In our current framework, all object locations (such as tables) are hard-coded so the robot has a lot of prior knowledge on where to find objects and how to manipulate them. Some folks in my group are coupling object detectors, SLAM, and shape estimation tools (from multiple RGB viewpoints or 3D point clouds) and building towards a more holistic semantic mapping approach. Could this potentially be integrated?
- Variety of projects: Generally, I think I’ll be jumping around projects more this upcoming year. While it’s bittersweet to ease off working exclusively with the capable robotic platform that is the HSR, I’m excited to be learning other things and hopefully working with more people than was the case this year. I may also get some teaching opportunities at MIT!
- Hands-on with C++: I worked mainly in Python this year, but I want to get more into C++ because it’s important to be well-versed in C++ for robotics as I comment in my programming languages blog post. I came into a C++ based project at the end of this year, but way more practice is needed.
- Hands-on with ROS 2: I don’t think I’ll get to use any ROS 2 on the job, since the technology is still on its way to widespread adoption (the HSR certainly has no short-term path to ROS 2). However, I have a new personal laptop ready to go and I’d like to try things out for my own edification. This should go well with the C++ goal since that’s one of the main ROS 2 client libraries.
Thank you for reading! If you want to chat about any of the work in this recap, have ideas for content I could share in the future, or have any suggestions in general, please reach out. Hope you all have a great 2021!
9 thoughts on “2020 in Review: Home Service Robotics at MIT CSAIL”
Comments are closed.