It’s time again for an annual recap post. This is a chance for me to reflect on what I did and learned over the past year, and share some of the key results and lessons learned with you!
My biggest highlight of 2021 is that halfway through the year (in July) I left my software engineer position at MIT CSAIL for another software engineer position at Boston Dynamics. Let me first express my complete disbelief that I’ve had the privilege to be part of both of these organizations, each of which is its own distinguished force in the world of robotics.
In last year’s recap post, I spoke about my home service robotics work with the Toyota HSR, which was almost all I worked on in 2020. However, that project actually ended in early 2021, so my boss at the time (Professor Nick Roy) was kind enough to transition me into a role where I could provide support in getting results for papers and/or collaborative experiments — or as he referred to it, “Special Forces”. This was a really cool opportunity in that, besides having my own software engineering project, I also got to collaborate with researchers within MIT and with other universities and organizations.
This part will skim through a few collaborative projects I got to take part in at MIT while also doing my main home service project, fully acknowledging that each project could easily have its own dedicated blog post. In the next post, I will discuss the second half of the year and my experience so far at Boston Dynamics.
Learning and Planning for Temporally Extended Tasks in Unknown Environments
The bulk of this work was actually done in 2020, but the paper wasn’t officially accepted until 2021. This was a continuation of the Learned Subgoal Planning work done by my then colleagues Greg Stein* and Chris Bradley, under the supervision of Professor Nick Roy. The extension that led to this publication additionally brought in my former advisor at Cornell, Professor Hadas Kress-Gazit, and her student Adam Pacheck. It was so cool getting to work with my advisor again after so many years.
* I should now say, Professor Gregory J Stein 🙂
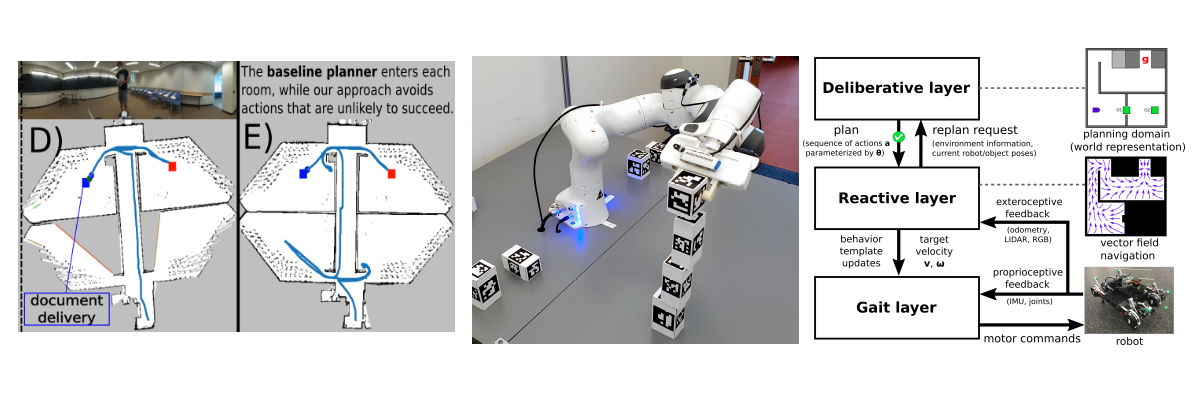
In the Learned Subgoal Planning paper, Greg and Chris came up with a way to bake learning from experience into decision-making for goal-directed navigation in partially revealed environments. As an example, suppose a robot is navigating down a hallway and sees a door to its left, but does not know how the world looks beyond either of these “subgoals”. With no additional knowledge, it is impossible to decide whether driving through the door or continuing down the hallway is the best way to get to a goal location. However, suppose the robot has encountered similar decisions in the past, and had a camera to capture how these subgoals looked prior to choosing a subgoal and revealing more of its environment. This led to a learning-based approach that could use visual input from novel scenes and estimate the cost (or distance to the goal) of choosing one subgoal over the other.
Then, the Cornell collaboration came into the picture. Instead of the (relatively) simple task of navigating towards a goal, could we use the same learned subgoal planning approach for more complex tasks? Professor Kress-Gazit is known for her work in formal verification and planning from Linear Temporal Logic (LTL) specifications, as evidenced by her group’s name, Verifiable Robotics Research Group. So what if instead of learning how “good” a subgoal is at getting us closer to a goal, we can do the same for how a subgoal might help us progress in fulfilling a task specification using LTL?
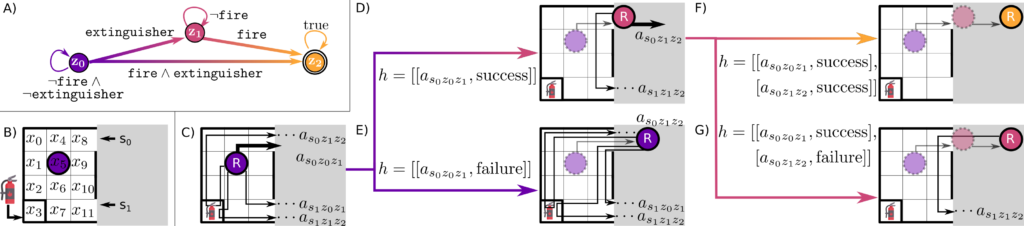
Indeed, my co-authors found that this worked in simulated experiments and were quite far along in this work when I was called to help produce real-world results. This was the summer that Chris and I strapped a Ricoh Theta panoramic camera to the head of our Toyota HSR and started driving down the empty halls of MIT (we were among the first batch of people allowed back on campus following the COVID-19). After a lot of challenges getting the relatively expensive neural network inference and Monte Carlo Tree Search software components running on a gaming laptop strapped to the back of the robot, as well as all the usual modifications to get “the thing that worked in simulation” also working in the real world, we were able to show some encouraging results! Please check out our paper which made it to ICRA 2021, and the accompanying video below.
I also want to add that my involvement in communicating this work (paper writing, figures, videos, etc.) taught me a shocking amount about automaton synthesis from LTL specifications and their applications for planning under formal guarantees — to the point that I tried using LTL for my work with the Toyota HSR, even if it eventually took a backseat to task specifications in Planning Domain Definition Language (PDDL) due to work at MIT that integrated this with continuous-space motion planning.
Active Learning of Abstract Plan Feasibility
I ended the previous project talking about ongoing work at MIT dealing with task and motion planning (TAMP) using PDDL. Unsurprisingly, this was work supervised by the TAMP legends, Professors Leslie Kaelbling and Tomás Lozano-Pérez. To say that I got to work on a project with them, along with the amazing students Michael Noseworthy, Caris Moses, and Izzy Brand, is one of the many things I will cherish about my time at MIT. Also, this work was sponsored by the Curious Minded Machine initiative at Honda Research Institute.
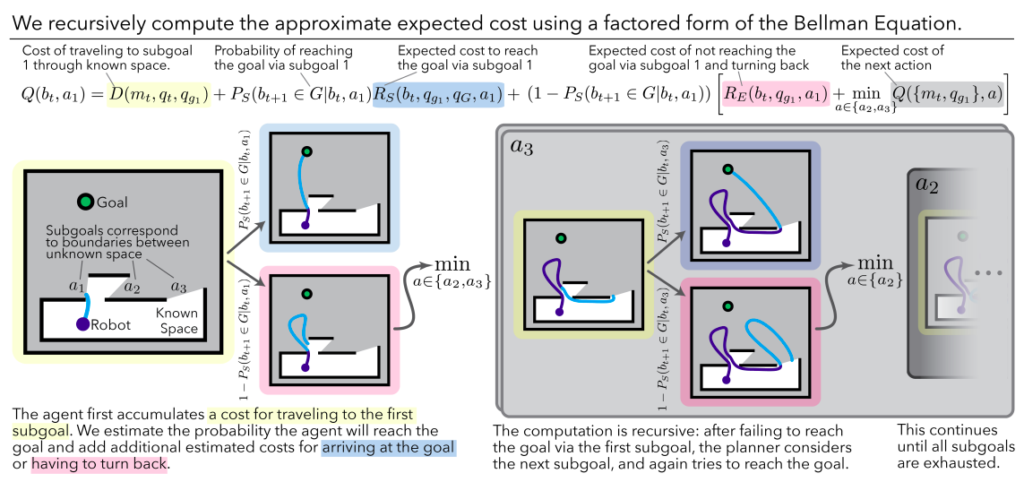
In this project, Mike, Caris, and Izzy had been working hard on a sample-efficient, self-supervised learning method to perform long-horizon manipulation tasks. Take the example of a robot trying to stack tall towers: Can our robot be equipped with a mechanism that can tell us which towers it should even bother attempting, in order to balance maximizing cost (what is the tallest tower possible?) and feasibility (will the tower be stable?). In this work, the idea was to learn a predictor for this Abstract Plan Feasibility (APF) in a way that doesn’t require a detailed physical model of the robot, its internal dynamics, and its interactions with the environment.
One solution would be to throw brute-force reinforcement learning (RL) at this problem. However, this traditionally requires an astonishing number of experiences (or samples for learning) to “stumble” upon certain discoveries that help push learning forward. This is especially tricky for real-world experiments, which is why so many RL “breakthroughs” are shown in simulation and why entire organizations devoted to RL have in the past opted to shut down their robotics divisions. By leveraging a method named Bayesian Active Learning by Disagreements (BALD), we could maintain an ensemble of models to give us an indication of uncertainty. Without getting into too much detail, we could make learning much more sample-efficient by employing an active learning approach: In our example, this meant sampling lots of towers, looking for the ones where the model ensemble is most uncertain about feasibility, and pick those for learning rather than sampling uniformly across “uninteresting” towers.
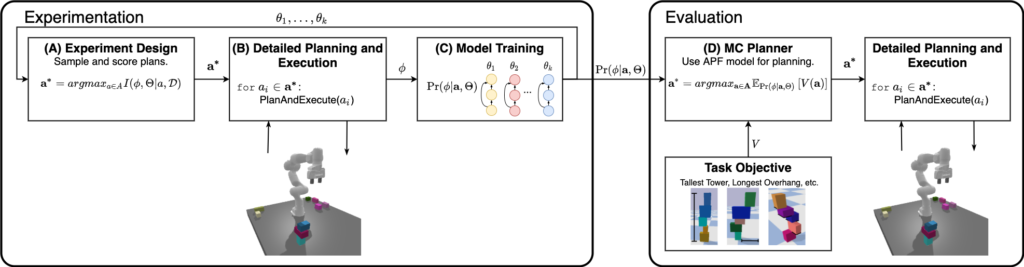
For this project, Mike, Caris, and Izzy had modified a PyBullet simulation of a Franka Emika Panda robot arm and were beginning to scale up their simulation experiments plus move towards the real robot. While I didn’t get to devote a whole lot of time to this work, my main contribution was to set up a distributed computing framework to allow the real-world experiments to run reliably and in a feasible amount of time. The constraints were as follows:
- There needs to be a dedicated PC running a Linux Real-Time Kernel (RTK) to maintain controls with the robot arm.
- Our planner, based on PDDLStream, was simultaneously reasoning over task planning (which blocks to pick and in which order) and motion planning (where should the block be grasped and how do we generate a collision-free trajectory?)… all in Python.
- The active learning framework needed to gather up all the experiences from the robot successfully or unsuccessfully stacking blocks, and when it gathered a sufficiently large batch it would train an ensemble of graph neural networks. We definitely could not do this step on the same PC with the RTK controlling the robots.
What we came up with as a two-PC solution as shown below, where ROS services were the key design paradigm we employed to communicate between components. We had three ROS nodes: learning, planning, and execution.
- The learning node would sample towers for the robot to try build and communicate this as a goal to the execution node.
- The execution node would break up the tower into N separate planning subgoals and send them in batch to the planning node, which would execute the expensive task and motion planner in a separate thread.
- As the planning node produces plans for each individual subgoal (i.e., moving an individual block), it communicates the detailed action list to the execution node and keeps planning for the next subgoal while the execution node makes the robot actually move. This parallelization was by far our most important speed-up which let us collect 400 hours of training data for our paper.
- Critically, if the robot failed to execute a plan or received new information about the world, the execution node was able to interrupt the planning node and send it a new world state from which to resume planning.
- Finally, the results of attempting to execute the whole plan (i.e. stacking a tower) would be communicated back to the learning node and the data would be written to file to keep track of the state of learning when we encountered inevitable hardware problems.
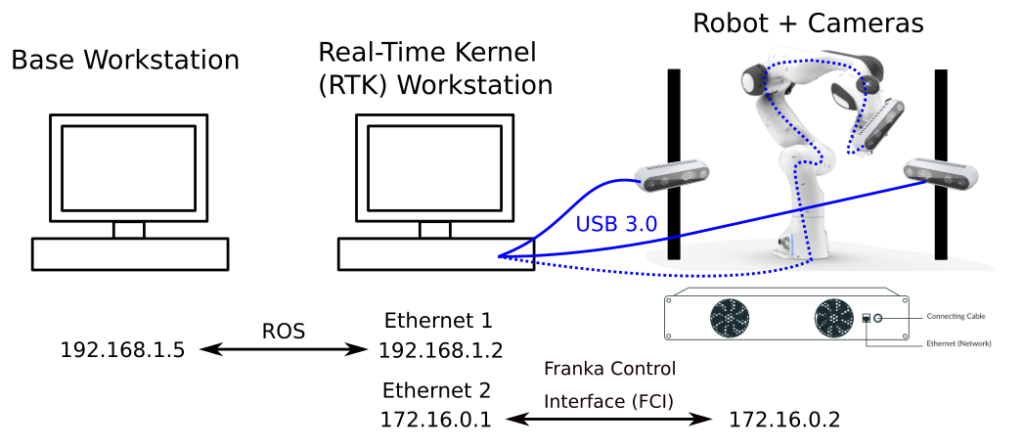
This was a tremendously fun project to work on. I got to cut my teeth on breaking up a fairly complex code base in a way that facilitated inter-process communication through ROS services, got experience working with the delightful robot that is the Franka Emika Panda, and got the immersive experience of scrambling to collect data around the clock with Mike, Caris, and Izzy. Our paper made it into RSS 2021, and you can also learn more from the GitHub repo and accompanying video below!
It’s also worth mentioning that Mike and Izzy were able to push this work even further in their Object-Factored Models with Partially Observed State paper, which made it to the Bayesian Deep Learning workshop at NeurIPS 2021.
A Hierarchical Deliberative-Reactive System Architecture for Task and Motion Planning
This project is still a work in progress in collaboration with Professor Dan Koditschek and his former student Vassilis Vasilopoulos, along with Will Vega-Brown who is a former student of Professor Nick Roy.
For some time before my arrival, there has been a long-standing discussion about integrating two systems: From MIT, a task and motion planning framework that uses constraints to reason over discrete and continuous variables, and from Penn a reactive controller based on vector fields that guarantees convergence to a goal even with complex environmental geometry and unforeseen obstacles. As with previous work, this was demonstrated on “Navigation Among Movable Obstacles” (NAMO) tasks with a quadrupedal robot.
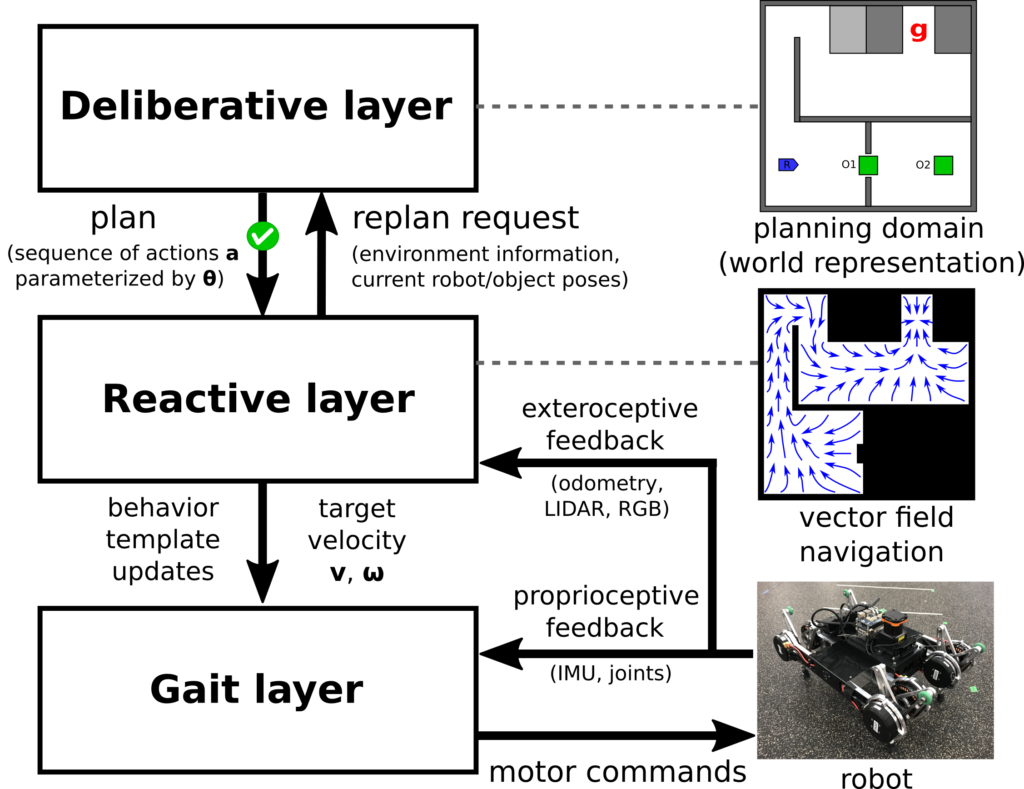
The idea was to see whether the formal guarantees (or the “contract”) provided by the reactive planner could simplify the higher-level, deliberative, task and motion planner to give overall improvements in computational performance and allow us to solve more complex tasks in less time. In other words, if we could simply say that two regions were adjacent to each other and the reactive controller could guarantee navigation between them if feasible, could the deliberative planner similarly reason at this level rather than having to produce a detailed motion plan consisting of low-level motion primitives that must be verified through expensive collision checks? Can’t the reactive layer take a lot of this computational burden away?
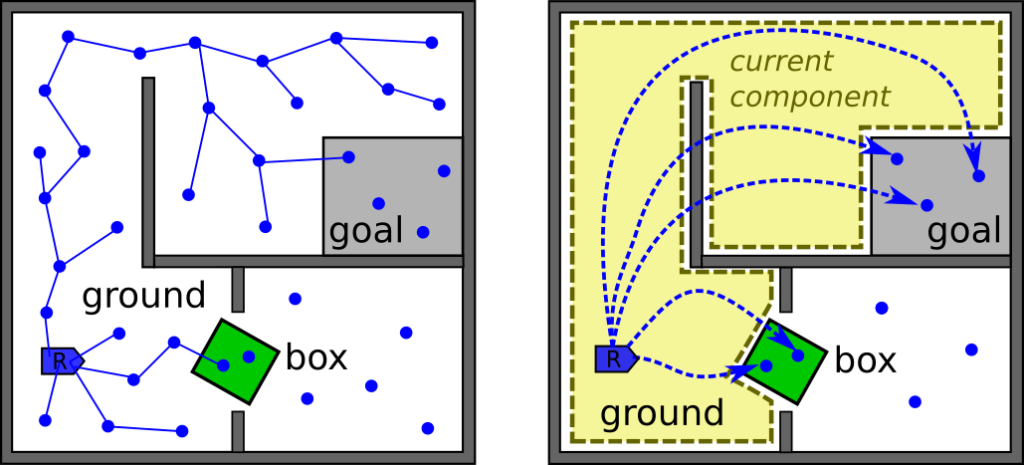
Right: Searching for a motion plan assuming a reactive layer guarantees navigation anywhere within the robot’s current connected component (highlighted in yellow).
I came into this project to provide the above integration support and see whether this idea could take off beyond the land of discussion and into practice. Our findings have been encouraging, in that the reactive controller from Penn excels at handling complex environments with narrow passageways and unanticipated obstacles in a way that very easily trips up the traditional task and motion planner. We were able to show this by melting our computers with quantitative experiments and qualitative system-level simulation experiments that compared the performance of the deliberative planner with and without taking into account the guarantees of the reactive controller.
This was a great learning experience for me in preparation for my current job at Boston Dynamics, in that it threw me right into the fire and got me the C++ programming experience I desperately needed, since Will’s task and motion planner was entirely written in C++. In the process, I got to use lots of cool tools and libraries to get the job done. These include:
- The Boost Geometry library to create adjacency graphs of polygons in our deliberative planning domain. This was my key contribution to this project, and by proving this out we were then able to push on getting experimental results and writing a paper.
- The C++ ROS client library to wrap the task and motion planner into a ROS service server that could be called by the downstream layers of the hierarchical system.
- The JSON for Modern C++ library. Since all domain specifications were parsed from JSON, I created ROS services to modify the planning world by adding/removing objects, changing initial conditions, etc. This was useful during our experiments when the robot discovered a new obstacle at runtime and needed to communicate it to the planner, but also for qualitative experiments where we had Python scripts randomizing worlds and stress-testing the planner.
- … and last, but not least, I got experience DEBUGGING C++. If you want to take anything away from this section, it is that gdb is awesome, that you can use it with ROS nodes, and that cgdb gives some extra visuals which I found super useful.
We are still in the process of finding a publication venue for this work (EDIT: This was accepted to ICRA 2022!), but you faithful readers get to see a sneak peek of the work in this video!
Conclusion
To summarize, my home service robotics project from the prior year along with the additional experiences from this post gave me an invaluable re-introduction to the real world of robotics. My time at MIT CSAIL was the perfect bridge that elevated me from teaching through simple demos to messing around with a highly capable robot in my own code base, and finally to contributing to large projects with well-established code bases, getting to publish with world-class research groups along the way.
MIT gave me an incredible year and a half of intellectual and technical freedom where I got to work on my non-MATLAB programming languages (notably, Python and C++), got an enormous amount of hands-on experience with ROS in that literally every project I worked on used it, and some software engineering chops in that our group was very thorough in its use of source control (Git repo with feature branches and a solid pull request review process), unit testing, and continuous integration/continuous development (CI/CD). I also got pretty good with Docker as a way to ensure code reproducibility and simply for context switching between all these projects without breaking my development environment. If you look back at my blog posts, you will notice that the topics covered track this paragraph by no mere coincidence.
I am deeply grateful to all my colleagues in the Robust Robotics Group, as well as the Learning and Intelligent Systems Group and Aerospace Controls Lab at MIT, the Verifiable Robotics Research Group at Cornell, and Kod*lab at the University of Pennsylvania. May we get to work again soon.
In the next post, I will continue the 2021 recap but shift focus to my new role at Boston Dynamics and how things are similar and different compared to my previous roles. Hope you enjoyed this extremely high-level overview of my “miscellaneous” MIT projects, and stay tuned!
Great content! Keep up the good work!